





 电话咨询:15810120570
电话咨询:15810120570
 公司邮箱:hi@hengshi.com
公司邮箱:hi@hengshi.com
 北京市海淀区西小口路66号中关村东升科技园B-2楼D201室
北京市海淀区西小口路66号中关村东升科技园B-2楼D201室
 上海市黄浦区延安东路550号海洋大厦29楼2903室
上海市黄浦区延安东路550号海洋大厦29楼2903室
 广东省深圳市光明区光源五路宝新科技园4栋707号
广东省深圳市光明区光源五路宝新科技园4栋707号

BI 的落地甚至比 BI 标准化产品的出现还要更早。由工程师定制化开发页面是最基本的方式,然后是通过 BI 厂商进行报表项目的实施交付,但最佳路径还是由客户自己进行自助分析,这在长期来看有巨大的成本差异,这包括了重复建设的工程成本和响应业务的时间成本。
定义澄清:BI 并不仅仅是指一种报表形态或者看板形态的制作工具,BI 是高度概述了一个组织根据数据有效提取洞见后辅助经营决策的形态。BI 是一个反复迭代的数据实践过程,也是一个数据驱动下的精细化运营状态。这个市场长青的原因在于:它体现了企业管理从 KPI 开始的目标导向管理理论,这方面的需求不随技术趋势改变。
商业智能是一个理想的形态,从全球市场来看,疫情后企业经营偏向务实增长和健康经营是推动 BI 市场进一步增长的主要因素,但是由于数据分析在任何行业都存在较高的专业门槛,应用 BI 技术的普及一直异常缓慢,主要体现在真正熟悉业务的需求方 — 业务运营人员无法真正参与到数据分析和计算过程中去,他们只能被动等待静态报表的提交和更新,并痛苦的向技术和数据团队反复阐述自己的分析意图,这极大阻碍了数据洞见的挖掘和流转。
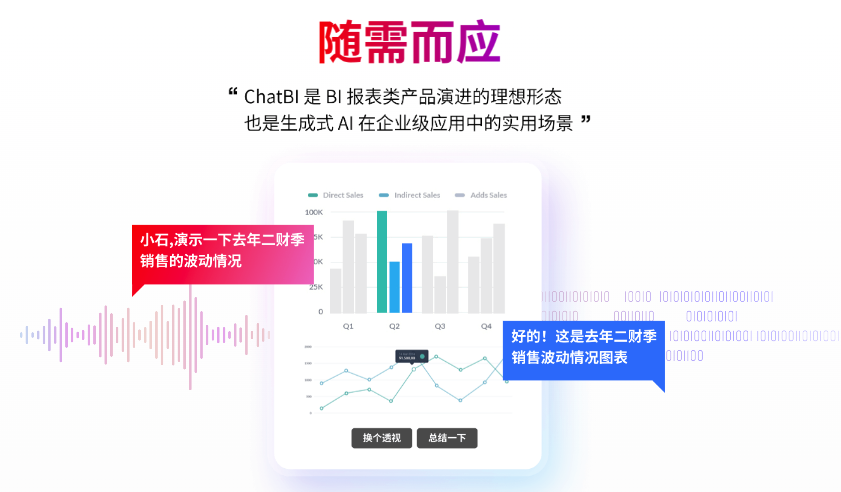
AI 从根本上直接击中了这个痛点,如果在相对闭包的场景内,在一定的准确率保证基础上,业务人员可以直接通过自然语言进行灵活的数据口径询问,这足以让 BI 链条里最关键却也是最低效的环节得到根本性改善,这将直接推动 BI 在各应用场景下的快速普及落地。
HENGSHI SENSE 5.2 创新概览
通过 BI PaaS 能力集成嵌入到管理应用将成为 BI 分析普及的主流形式
API 优先的架构推动了应用软件中的嵌入式商业智能和分析,和ERP、CRM等主流应用的整合让很多的分析动作自然发生在场景内,客户由此得以逃离僵化和高成本的BI项目。同时解决方案优先的国内市场客户,也更加青睐整合进应用场景的分析和报表呈现,这降低了数据导出-集中-重新建模-报表构建-讲述故事的建设成本。
企业客户的直接推动和应用厂商对业务价值的智能化探索,都让嵌入整合的 BI 分析成为一个务实、低成本、快速见效的合作形式,毕竟谁不希望一个应用软件可以通过增加 BI 解决方案来促进市场销售呢,特别是 BI 解决方案正在快速 AI 化的今天。
PaaS的本质是低成本灵活构建,因此使用 BI PaaS 非常类似在零代码的构建分析场景,我们希望国内的应用软件厂商不需要再数百万甚至数千万的以年为单位浪费研发成本,直接使用 BI PaaS 这样的成熟产品,让商业分析即刻上线。
灵活的探索型分析是生成式 AI 落地最实用场景,Data + AI 正在迅速成为主流
生成式 AI 对于 ToB 场景的能力还不稳定,特别在数据分析和 BI 场景,数据模型的复杂性和精确性是大语言模型短期内无法攻克的难题。
和能力的不足够形成对比的是需求的涌现,被 AI 点燃的客户们逐渐把智能化的诉求放在运营层面。最近 Databricks和 Snowflake 的峰会都不约而同的阐明了接下来数据行业的主题:Data + AI。一个随需应变的数据分析 AI 助手足以让运营控和数据控的管理人员为之倾倒,而这里我们看到在实际的市场中非常明确清晰的需求,恰恰来自之前的 BI 用户群体,这些熟知业务分析逻辑和指标体系奥妙的顶尖高手,在第一时间看到了技术落地的现实可能。
在过去半年的实践中,衡石团队有一半的精力在提升 AI 问答的准确率,而另一半的精力在控制客户的预期。我们能够做到在 BI 的合理建设基础上,和相对闭包确定的业务场景中,可落地的高准确率,这是 BI + AI 的最佳实践,最终形态体现为 ChatBI。但是衡石提供的方案区别于大多数重度依赖大模型的 ChatBI,我们基于 BI 平台和 BI 的建设,由此获得非常可靠的权限控制和较为可靠的准确度保障,我们甚至建议我们的客户从 BI 建设开始走入 AI 旅程,这是构建人机对话的语料库。当然,我们的下一步工作,是让构建 BI 的过程,也变得更加智能和轻松。
HENGSHI SENSE 5.2 亮点功能一览
HENGSHI SENSE 发布 5.2 版本。在应用、数据管理和建模、可视化分析、交互优化等方面增加许多客户期待已久的许多功能。下面让我们一起来了解其中的亮点内容吧。
应用集市
数据管理和数据建模
可视化控件
交互体验升级
应用集市
在消费一个数据分析应用时,一般用仪表盘的列表形式作为分析结果展示形式。仪表盘和仪表盘之间,或者图表和仪表盘之间用联动跳转的方式来构筑隐式的数据关系。在相对简单的场景中这是足够简单和易用的方式,但这显然不是唯一的方式。客户经常也需要在仪表盘之上构建一个更加层级化的逻辑,因此在这个版本中我们针对客户的这个需求推出了数据门户的功能,一个应用可以以门户的形态进行仪表盘的浏览。
数据门户
数据门户以更加直观,且更加有逻辑的方式来组织数据应用,使得数量较多的仪表盘以及其他页面能够以一个统一菜单入口的方式来供业务人员来使用。数据门户是针对更高阶的数据应用组织需求而设计的。
数据门户包含了一组菜单配置,根据需求菜单可以配置为任意1到N级,每一个层级上都可以添加若干个分组或者页面。页面可以是一个应用内的仪表盘或者一个外部的URL。而一个分组内部可以在放置其他分组或者页面,这样就构成了门户的菜单层级结构。
原图:
应用创作区提供给应用的管理者和编辑者对门户的编辑和预览功能,可以分别针对桌面和移动端视图进行配置与预览。用户在发布态应用集市中查看该应用就会呈现门户的形态。如果我们的应用支持移动端那么可以进行移动端的门户设置,如果支持电脑端那么可以进行电脑端的门户设置,如果两者都支持,那么就需要分别设置电脑端和移动端的门户。当然一般我们也可以先配置好一个端,然后通过快捷的配置同步功能,一键将移动端的门户配置同步到电脑端,或者反之。
AI分析助手优化
准确性是AI分析分析助手的在体验上的最核心指标。在本次更新中,我们针对正确性引入了大量的RAG的辅助优化。
1.针对Schema的的向量化检索,能够对用户不精确问题,匹配到最相关的指标和维度,这样给到大模型的提示都是和用户问题具有高度关联性的schema,帮助大模型得到对用户意图较准确的理解。
2.针对维度高频值的倒排索引,对用户过滤条件以及维度信息做模糊的匹配。通过倒排索引,我们能够匹配到用户对于具体值的问题,转化成指标查询中精确维度的相似对象的检索。例如用户问题中“登山服”的检索,能够智能的转化成“商品大类中类目等于登山羽绒服”的准确过滤,这在以往的查询助手中,需要用户自己反复提问,才能得到这样一个理想的结果。通过这个技术,我们达成了用户无需在指定准确数据存储字段的前提下的一个智能响应。
3.针对行业问题回答范式的向量化检索。在每个行业中,都有一些所谓的“行业黑话”,对应的其实是在本行业内通行的一些指标计算方式,这个量可以是一个比较丰富的问题答案题库。在管理端,我们提供了用户对这个题库的自定义能力,在大模型查询交互中,我们利用向量匹配的题库给予最相关的 prompt,控制大模型准确地生成复杂的业务计算。
数据管理和数据建模
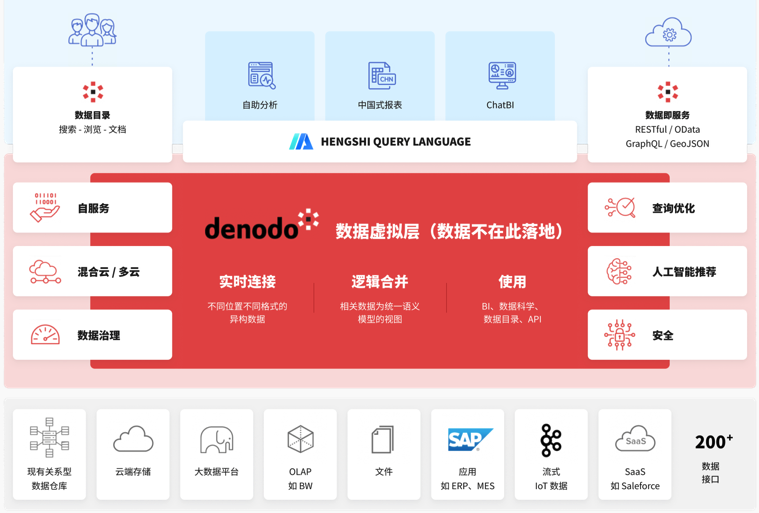
数据连接支持Denodo
Denodo是一个典型数据虚拟化平台,其主要产品Denodo Platform用于数据集成和管理。通过Denodo平台的虚拟化技术,可以构建单一的数据访问层,达到实时访问分散在不同位置和系统中的数据的效果。在本次版本更新中,我们带来的Denodo数据源的原生支持。结合Denodo的数据管理和衡石的数据分析能力,整合不同来源的数据,以全链路ELT的方式来提供统一的数据视图,更加敏捷地完成复杂的分析和报表需求。
环比支持上一周期
在中文语境下的同比、环比,在英文语境下的MoM、QoQ、YoY,它们的传统意义一般是按照自然月,自然季度,自然年为单位进行对比。例如 一般而言2024/06/01到2024/06/18的销量年同比增长是指对比上一年同期也就是2023/06/01到2023/06/18这段时间的增长,而月环比增长则是对比2024/05/01到2024/05/18这段时间的增长。但是事情总是有例外,有时候我们希望按指定的步长来对比上一个连续的周期。例如2023/06/01到2023/06/18这段时间有18天,我们希望看它和它的紧邻的18天也就是2023/06/13到2023/06/30做一个对比,观察618大促的即时状态,那么就可以使用同环比中的对比上一周期功能。
支持MySQL、ADB、StarRocks的JSON数组拆分
JSON的Schema-Free的特性对持续上线新功能的应用程序来说非常方便,因此JSON广泛应用于Web开发和日志统计中。因此我们也经常会遇到一个JSON记录中有多个记录放到一行中的情况。在一般的BI开发过程中,需要通过ETL过程将一行JSON的数组拆分成多行来存储,让分析的链路过于冗长。在新版本中可以对上述数据类型以及衡石引擎中中,可以直接对JSON类型的数组进行即时的动态拆分而无需ETL过程。例如
[ { "event": "查看", "cnt": 100 }, { "event": "点击", "cnt": 10 } ][ { "event": "查看", "cnt": 200 }, { "event": "点击", "cnt": 20 }, { "event": "购买", "cnt": 2 } ][ { "event": "查看", "cnt": 300 } ]
可以拆分成如下的数据
event | cnt |
查看 | 100 |
点击 | 10 |
查看 | 200 |
点击 | 20 |
购买 | 2 |
查看 | 300 |
复合数据集数据更新时可以忽略上游依赖触发事件
对很多用户来说复合数据集是高频使用的功能,例如联合数据集,合并数据集,聚合数据集等。将复合数据集导入引擎的时候有时候会遇到一个问题,就是其上游数据集也是导入引擎的状态,且更新比较频繁的情况下,会触发这个复合数据集的更新。有时候我们希望复合数据集有一个自己的更新计划不被上游数据集触发,减少数据同步和写入的压力。新版本中可以在数据集的更新设置中找到这个功能。
可视化控件
多边形的地理区域图
GeoJSON是一个常用的地理位置信息存储标准,它可以用一致的数据结构存储地理位置中关于点、线、多边形、组合多边形等等概念。在衡石5.2功能更新中,我们提供了对PostGIS中地理位置信息的读取和加载,转化成标准的GeoJSON格式,并且在地图中新增了多边形的图层。通过这个新图层,用户可以灵活定义自己的地理围栏,而不需要局限于标准地图。
图表组件新增指标趋势卡控件
指标趋势可以在查看指标总值的同时,展现指标的时间趋势。
对数坐标轴
在数据分析和展示的过程中,有时候我们会遇到不同分组的数据的量级差距非常大的情况。例如统计微生物的数量,某一些时刻是个位数,某些时刻是几万个,而另外一些时刻是几万亿个,如果用常规的图形,那么因为线性坐标轴很难展示从1到万亿的数据,导致小量的数据都在0附近。
对数坐标轴可以将数值范围很广的数据压缩到一个图表中,使得数据的不同量级在同一图表上更易于观察,可以清晰地看到各个数量级的数据变化。
数据集过滤器
和其他过滤器不同,数据集过滤器的主要配置项是一个数据集,而不是字段。当我们在设计仪表盘的交互时如果能够确定希望给于查看者的筛选字段,一般用其他普通过滤器是最稳妥的方式。但是如果我们在设计仪表盘的时候,不太确定查看者用于查询的字段有哪些,或者是希望给予查看者更多的筛选能力,则可以考虑使用数据集过滤器。
由于数据集过滤器是一个功能比较强大,但是对普通用户的使用相对来说比较复杂一些的功能,因此在设计仪表盘的时候要谨慎使用。另外由于该控件布局要求比较大的展示空间,所以它也不能在侧边栏中使用。
参数控件支持树形
树形参数控件适用于一个控件来控制多个参数,并且多个参数之间是有层级关系的情况。例如公司包含部门,部门包含员工;或者地区包含省份这样层级结构,让用户在选择参数控件的时候更方便定位到指定的选项。
交互体验升级
拼音搜索
值得一提的是呼声很高的拼音搜索目前已经上线,大部分支持页面搜索或过滤的功能原来只能用英文原文或者汉字来搜索,在新版本中可以用拼音前缀来搜索了,使用上应该会方便不少。
青苔满地初晴后,绿树无人昼梦余。
HENGSHI SENSE 5.2 作为新一代AI增强 BI 平台的更新版本 ,进一步提升AI Copilot的准确性和响应性能。应用门户的新形态也是 BI 场景的一个系统性创新。Denodo 的接入和更多数据源的复合数据类型的动态拆分持续地在提升 ELT 分析范式的适应能力。当然,诸多控件和交互的改进也让面向业务的场景搭建更智能、更便捷、更灵活,欢迎您来试用。
水晶帘动微风起,满架蔷薇一院香。
HENGSHI SENSE 5.3 汲取阳光,发荣滋长,开创更多数据分析的精彩功能,敬请期待!


电话咨询:15810120570
公司邮箱:hi@hengshi.com
北京市海淀区西小口路66号中关村东升科技园B-2楼D201室
上海市黄浦区延安东路550号海洋大厦29楼2903室
广东省深圳市光明区光源五路宝新科技园4栋707号
扫码关注

